首页 > 视频画质增强技巧 > 视频降噪模型轻量化:让AI修复轻装上阵,画质与速度兼得
视频降噪模型轻量化:让AI修复轻装上阵,画质与速度兼得
随着高分辨率视频的普及,低光照环境下的噪点问题愈发显著。传统的视频降噪处理往往依赖于庞大的计算资源,导致渲染时间过长或对硬件配置要求极高。在此背景下,视频降噪模型轻量化设计成为兼顾画质提升与处理效率的关键。这种设计思路通过优化算法网络结构,在维持画质细节的前提下,大幅降低了模型的计算复杂度和内存占用。目前数字处理领域存在多种基于轻量化架构的降噪工具与技术路径,为不同硬件条件的终端设备提供了高效的画面净化支持。
一、为什么视频降噪模型必须轻量化?
随着AI视频修复技术的普及,用户不再满足于简单的锐化或放大,而是希望实时、流畅地处理低画质视频。然而,传统高性能降噪模型往往参数量巨大,计算复杂度高,对GPU显存和算力要求苛刻——这导致很多用户只能在高端台式机上运行,无法在笔记本电脑、手机或实时直播场景中应用。轻量化设计因此成为产业落地的关键突破口。
具体痛点包括:
- 算力鸿沟:复杂模型(如BSRGAN、Real-ESRGAN)单帧处理耗时数秒,无法满足实时需求
- 内存占用:大模型导致显存溢出,普通设备无法加载
- 能效比低下:移动设备电池难以支撑高负载推理
- 部署困难:嵌入式设备(安防摄像头、无人机)缺乏AI算力支持
轻量化降噪模型的核心目标就是在保持相当降噪效果的前提下,大幅压缩模型体积、减少计算量,使AI修复能够跑在更多终端设备上。
二、传统降噪模型为何难以普及?
很多人认为“模型越大效果越好”,但实际应用中,传统降噪方案存在明显局限:
- 盲目堆叠卷积层数,导致参数量爆炸(动辄上百MB)
- 缺少针对移动端的算子优化,CPU/GPU推理效率低下
- 没有考虑时域信息,逐帧独立处理造成闪烁和额外计算开销
- 缺乏模型剪枝、量化等压缩手段,直接部署后发热、卡顿严重
因此,近年来研究者开始从网络结构设计(如MobileNet、ShuffleNet)、知识蒸馏、神经网络架构搜索等方向探索轻量化降噪模型。
三、轻量化降噪模型如何实现“小而强”?
轻量化并非简单“砍掉层数”,而是通过一系列核心技术达到效果与效率的平衡:
- 深度可分离卷积:将标准卷积分解为逐通道卷积和逐点卷积,计算量降至原来的1/8~1/9
- 特征复用与跳跃连接:减少冗余计算,增强梯度流动(如U-Net轻量化变体)
- 模型量化与剪枝:将FP32模型压缩为INT8,体积缩小4倍,推理加速2-3倍
- 时域稀疏注意力:利用前后帧相关性,只对变化区域进行高精度计算,大幅降低单帧开销
- 知识蒸馏:用大模型(教师)指导小模型(学生)学习,保持精度同时压缩参数量
通过上述技术,轻量化降噪模型可以在中低端GPU上实现1080p@30fps的实时降噪,参数量控制在5MB以内,效果接近大模型的90%以上。
四、主流轻量化视频降噪方案推荐与解析
目前市面上已有不少产品将轻量化降噪落地,以下推荐几款代表性方案:
1. HitPaw牛小影
HitPaw牛小影采用自研的轻量级AI推理框架,在保证高画质修复的前提下,显著降低了对硬件的依赖。其降噪模型经过深度剪枝和INT8量化,在普通集成显卡上即可流畅处理1080p视频,而不会出现过热或卡顿。特别适合笔记本用户和短视频创作者。
轻量化技术亮点:
- 动态推理图优化:根据视频内容自动选择最低计算路径
- 混合精度推理:关键层FP16,非关键层INT8,平衡精度与速度
- 端到端硬件适配:针对Intel核显、Apple M系列芯片专项优化
- 内存复用机制:单帧显存占用<500MB,支持4K视频批处理
使用步骤:
第一步:选择AI模型并导入视频
打开HitPaw牛小影,在主界面选择“通用降噪”或“视频增强”模型(两者均包含色度降噪能力),点击【直接使用】导入待处理的视频文件。
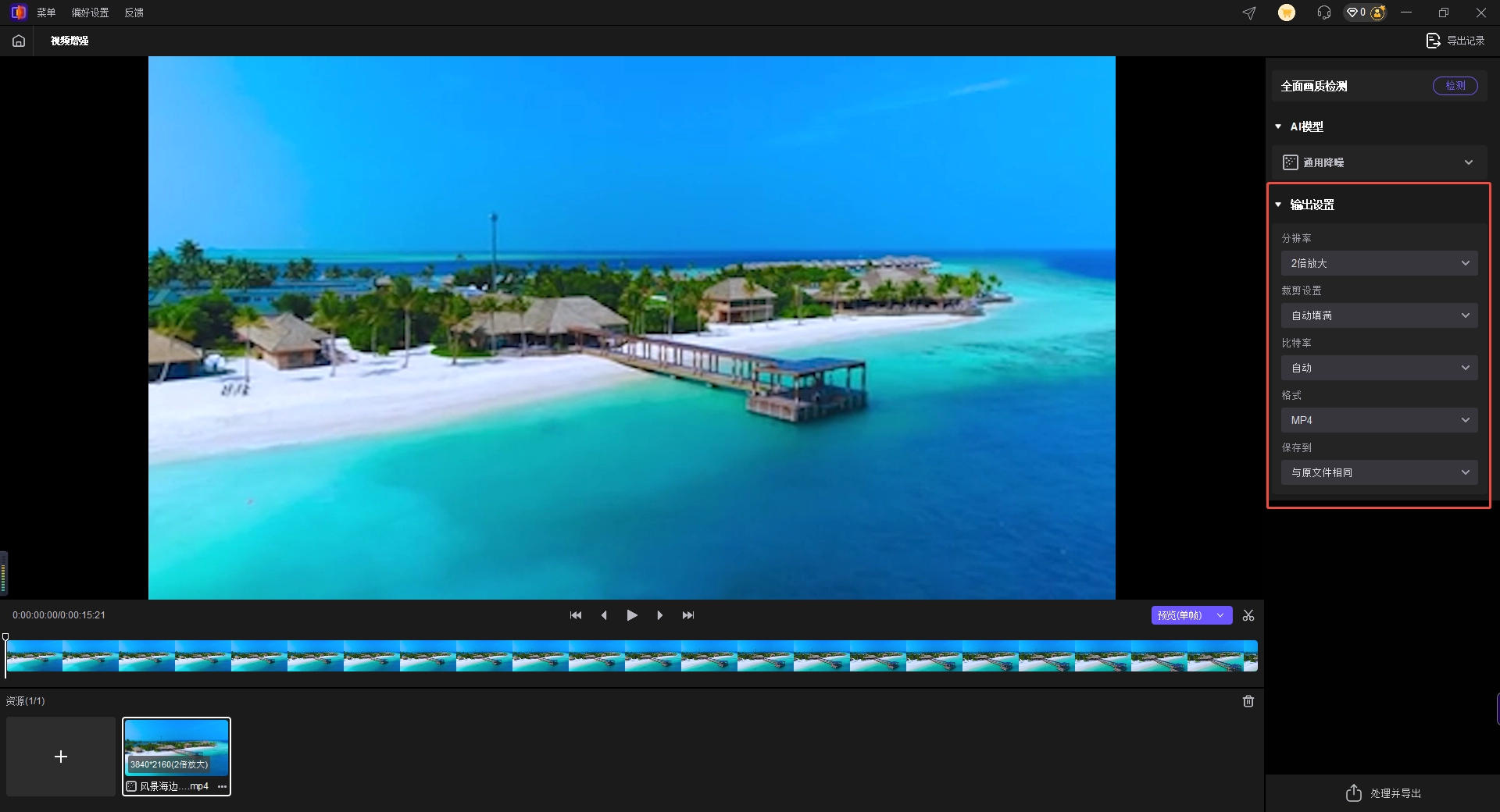
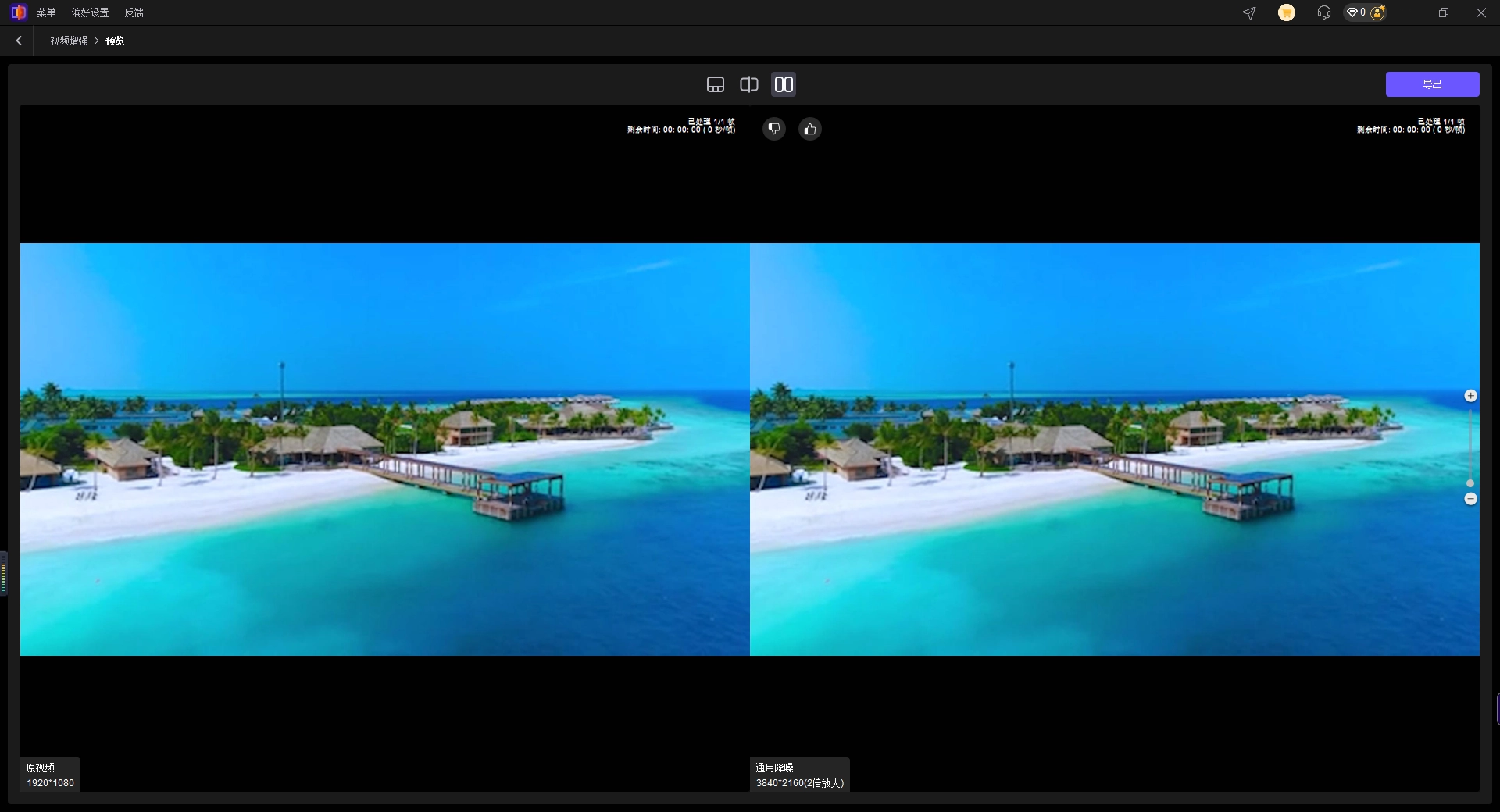
第二步:设置输出参数并预览
可以根据需要选择目标分辨率(如4K)、比特率等。强烈建议先点击“预览”按钮,选择10-30秒片段测试降噪效果,观察彩色噪点是否有效去除,同时注意肤色和色彩是否自然。
第三步:导出修复后的视频
确认预览效果满意后,点击【导出】按钮,等待软件处理完成。完成后对比原视频,色度噪声将明显减少,色彩更加纯净。
修复效果满意后,点击【导出】完成最终保存。
2. Real-CUGAN
Real-CUGAN 是一个经典的开源视频/图像降噪与超分模型,其作者提供了轻量版(-lite)权重,参数量仅为标准版的1/3,推理速度提升2倍以上。适合开发者集成到自己的应用中,支持ONNX、NCNN等多平台部署。
主要特点:
- 采用残差模块剪枝,保留降噪核心能力
- 支持动态输入尺寸,无需固定分辨率
- 提供预编译的移动端demo(Android/iOS)
- 与标准版效果差距<5%,但速度优势明显
3. NVIDIA Maxine
NVIDIA Maxine 是一套面向实时通信的AI SDK,其降噪模型经过极致轻量化设计,能在GPU上以极低延迟处理音频和视频。虽然依赖NVIDIA显卡,但模型本身的参数量极小,适合直播、视频会议等场景。
技术特点:
- 时域递归网络,利用历史帧信息降低单帧计算量
- 可配置精度等级,根据带宽和算力动态调整
- 与RTX语音降噪类似,延迟低于10ms
总结:视频降噪模型的轻量化设计是AI修复技术从“实验室”走向“大众应用”的关键一步。通过深度可分离卷积、模型量化、知识蒸馏等手段,如今的轻量模型已经能够在集成显卡、移动芯片上流畅运行,而画质损失微乎其微。无论你是普通用户希望快速处理家庭视频,还是开发者需要集成实时降噪能力,选择一款具备轻量化引擎的工具(如HitPaw牛小影)或开源方案(Real-CUGAN-lite)都将大幅提升效率与体验。